وقتی ARP Flood رخ میدهد داخل سوئیچ چه اتفاقی میافتد؟
سه شنبه ۵ اسفند ۰۴ | ۱۰:۰۰

در شبکههای لایه دوم، بسیاری از مشکلاتی که به شکل کندی ناگهانی، Drop شدن پکتها یا حتی قطع کامل ارتباط دیده میشوند، ریشه در رفتارهای غیرعادی ترافیک Broadcast دارند. یکی از مهمترین این رفتارها، ARP Flood است. شاید در ظاهر فقط با افزایش ARP Request در Wireshark مواجه شوید، اما در سطح داخلی سوئیچ اتفاقات پیچیدهتری در حال رخ دادن است. درک اینکه هنگام ARP Flood دقیقاً چه اتفاقی داخل ASIC، CAM Table و بافرهای سوئیچ (الخصوص سوئیچ سیسکو) میافتد، برای هر مهندس شبکهای که با تجهیزات حرفهای کار میکند ضروری است.
در این مقاله، رفتار داخلی سوئیچ در زمان ARP Flood را از دید فنی و معماری بررسی میکنیم؛ از نحوه پردازش Broadcast در لایه دو گرفته تا تأثیر آن روی Switching Fabric، Buffer Architecture و حتی CPU Control Plane.
ARP به زبان فنی: چرا اصلاً Broadcast است؟
پروتکل Address Resolution Protocol یا ARP برای نگاشت IP به MAC در شبکههای IPv4 استفاده میشود. زمانی که یک میزبان میخواهد IP مقصدی را در همان Subnet پیدا کند اما MAC آن را نمیداند، یک ARP Request به صورت Broadcast ارسال میکند. این فریم با MAC مقصد FF:FF:FF:FF:FF:FF در VLAN مربوطه منتشر میشود.
سوئیچ در لایه دو ذاتاً با Broadcast مشکلی ندارد؛ چون برای چنین فریمهایی باید Flood انجام دهد. یعنی فریم را به تمام پورتهای همان VLAN، بهجز پورتی که از آن وارد شده، ارسال کند. این رفتار طبیعی است. مشکل زمانی آغاز میشود که تعداد این Broadcastها از حد نرمال عبور کند و به وضعیت Flood غیرعادی برسد.
آغاز ARP Flood: اولین واکنش سوئیچ
زمانی که تعداد زیادی ARP Request در مدت زمان کوتاه وارد سوئیچ میشوند، اولین اتفاق در Data Plane رخ میدهد. هر فریم ARP مانند هر فریم دیگر ابتدا وارد ورودی ASIC میشود. در این مرحله، سوئیچ MAC Source را در CAM Table یاد میگیرد یا بهروزرسانی میکند. سپس به دلیل Broadcast بودن مقصد، تصمیم Forwarding آن ساده است: Flood در همان VLAN.
اما وقتی این فرآیند هزاران بار در ثانیه تکرار شود، چند اتفاق همزمان رخ میدهد. CAM Table با حجم زیادی از Update مواجه میشود. بافرهای خروجی برای هر پورت شروع به پر شدن میکنند، زیرا هر Broadcast باید به همه پورتها ارسال شود. اگر Uplink محدود باشد، نسبت Oversubscription به سرعت افزایش مییابد. در این مرحله هنوز ممکن است همه چیز سبز به نظر برسد؛ Interfaceها Up هستند و CRC Error نداریم. اما در عمق سوئیچ، منابع در حال مصرف شدن هستند.
تأثیر ARP Flood بر CAM Table
CAM Table یا همان MAC Address Table ظرفیت محدودی دارد. در سوئیچهای Enterprise این ظرفیت ممکن است دهها هزار Entry باشد، اما بینهایت نیست. اگر ARP Flood ناشی از یک حمله Spoofing یا ابزارهایی مانند ARP Scan باشد، هر ARP Request میتواند با MAC Source متفاوتی ارسال شود.
در این حالت، سوئیچ مجبور میشود MACهای جدید را یاد بگیرد. اگر تعداد MACهای جعلی از ظرفیت CAM عبور کند، پدیدهای به نام CAM Table Exhaustion رخ میدهد. وقتی جدول پر شود، سوئیچ دیگر قادر به یادگیری MAC جدید نیست و برای فریمهایی که مقصدشان در جدول نیست، Flood انجام میدهد.
نتیجه این رفتار، تبدیل شدن شبکه به یک محیط شبه-Hub است. یعنی بخش بزرگی از ترافیک Unicast نیز به شکل Flood ارسال میشود. این همان نقطهای است که کاربران عملاً با کندی شدید یا اختلال کامل مواجه میشوند.
فشار روی Buffer و Queueها
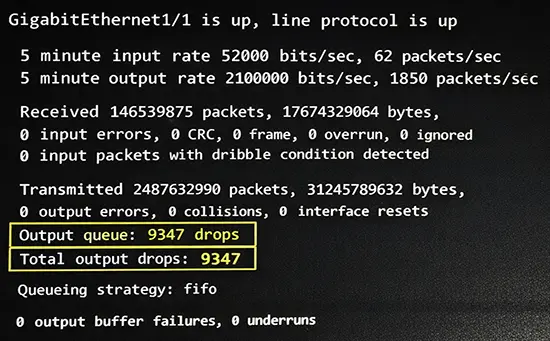
در معماری سوئیچهای حرفهای، مانند خانواده Catalyst یا Nexus، هر پورت دارای Queueهای خروجی و ساختار Buffer مخصوص است. زمانی که ARP Flood رخ میدهد، حجم زیادی از Broadcast باید در صف هر پورت قرار گیرد. اگر پورت مقصد سرعت پایینتری داشته باشد یا Uplink محدود باشد، صف آن سریعتر پر میشود. وقتی Queue پر شود، Drop در لایه خروجی رخ میدهد. این Drop ممکن است در Output Queue دیده شود، بدون اینکه Input Error یا CRC داشته باشید.
بسیاری از مهندسان فقط به خطاهای فیزیکی توجه میکنند، در حالی که در ARP Flood، Drop کاملاً منطقی و ناشی از ازدحام داخلی است. در سوئیچهایی با Shared Buffer Architecture، فشار Broadcast ممکن است منابع بافر را از سایر ترافیکها نیز بگیرد. در نتیجه حتی ترافیک مهم مانند Voice یا Storage نیز دچار تأخیر یا Packet Loss میشود.
اثر روی Switching Fabric
Switching Fabric ظرفیت مشخصی دارد که معمولاً با عنوان Switching Capacity اعلام میشود. اما این عدد تئوریک است. در عمل، Broadcast سنگین میتواند Fabric را درگیر کند، مخصوصاً اگر چندین VLAN همزمان درگیر باشند. اگر ARP Flood از چندین Access Port وارد شود و به Uplink محدودی ختم گردد، Oversubscription Ratio بالا میرود. اینجا Fabric ممکن است توانایی پردازش همزمان تمام فریمها را داشته باشد، اما Uplink گلوگاه خواهد بود. نتیجه، افزایش Latency و سپس Drop است.
Control Plane و افزایش CPU
در حالت عادی، ARP در لایه دو توسط ASIC مدیریت میشود و CPU درگیر نمیشود. اما در برخی شرایط، مانند فعال بودن ARP Inspection یا ویژگیهای امنیتی، بخشی از ترافیک ARP ممکن است به CPU ارسال شود. در این حالت، ARP Flood میتواند باعث افزایش شدید CPU شود. اگر CPU به بالای 80 یا 90 درصد برسد، حتی فرآیندهای مدیریتی مانند SNMP یا SSH نیز دچار کندی میشوند. در برخی مدلها، اگر Control Plane Protection بهدرستی تنظیم نشده باشد، CPU Starvation رخ میدهد. در این شرایط، شما علاوه بر Drop در Data Plane، با کاهش پاسخگویی مدیریتی سوئیچ نیز مواجه خواهید شد.
سناریوی عملی در یک شبکه سازمانی
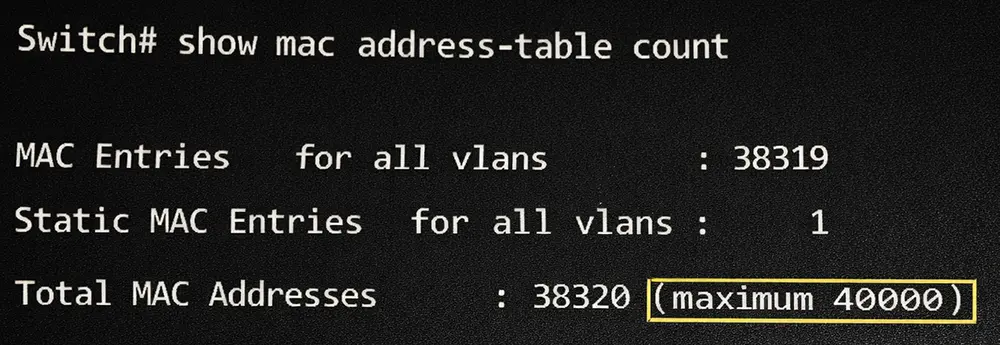
فرض کنید در یک شبکه Campus با سوئیچهای سری Catalyst، یک سیستم آلوده شروع به ارسال ARP Request با IPهای متوالی میکند. این ترافیک از یک Access Port وارد میشود و در همان VLAN منتشر میشود. در ابتدا فقط افزایش Broadcast دیده میشود. سپس MAC Table شروع به پر شدن میکند. اگر محدودیتی روی تعداد MAC در هر پورت تعریف نشده باشد، Entryهای جعلی به سرعت ثبت میشوند. پس از پر شدن جدول، سوئیچ دیگر نمیتواند MAC واقعی کاربران را یاد بگیرد و ترافیک Unicast نیز Flood میشود.
کاربران شروع به گزارش کندی میکنند. در خروجی show interface ممکن است Output Drops افزایش یابد، در حالی که هیچ CRC Error یا Collision دیده نمیشود. اگر بررسی عمیقتری انجام شود، تعداد Broadcast در ثانیه به شکل غیرعادی بالا خواهد بود.
تفاوت رفتار در سوئیچهای دیتاسنتر
در سوئیچهای دیتاسنتر مانند سری Nexus، معماری Buffer و Fabric پیشرفتهتر است. اما ARP Flood همچنان میتواند مشکلساز باشد، بهخصوص در شبکههایی با تعداد زیاد Host یا ماشین مجازی. در محیطهای مجازیسازی، هر VM میتواند ARP ارسال کند. اگر Loop یا Misconfiguration وجود داشته باشد، Broadcast Storm در مقیاس بزرگ رخ میدهد. در این حالت حتی Fabric قدرتمند نیز نمیتواند از Saturation جلوگیری کند، زیرا ماهیت Broadcast ذاتاً تکثیرشونده است.
چرا ARP Flood گاهی با Loop اشتباه گرفته میشود؟
از نظر علائم، ARP Flood شباهت زیادی به Broadcast Storm ناشی از Loop دارد. هر دو باعث افزایش Broadcast، بالا رفتن Utilization و Drop میشوند. اما تفاوت کلیدی در منبع تولید ترافیک است. در Loop، یک فریم Broadcast بارها در شبکه میچرخد و تکثیر میشود. در ARP Flood، منبع اصلی یک یا چند Host هستند که عمداً یا ناخواسته ARP تولید میکنند. از نظر داخلی سوئیچ، هر دو باعث فشار روی Buffer و CAM میشوند، اما الگوی ترافیک متفاوت است.
تأثیر روی QoS و ترافیک حساس
اگر QoS بهدرستی تنظیم نشده باشد، Broadcast ممکن است با اولویت برابر با سایر ترافیکها پردازش شود. در نتیجه Voice VLAN یا ترافیک حساس به Latency نیز آسیب میبیند. حتی اگر Queueهای جداگانه تعریف شده باشند، اشباع Fabric یا Uplink میتواند همه کلاسها را تحت تأثیر قرار دهد. در شبکههایی که تلفنهای IP یا سیستمهای ویدئوکنفرانس دارند، ARP Flood میتواند به شکل قطع تماس یا Jitter شدید ظاهر شود.
چگونه داخل سوئیچ متوجه ARP Flood شویم؟
بررسی افزایش Broadcast Rate اولین قدم است. سپس باید به CAM Utilization نگاه کرد. در برخی سوئیچها میتوان درصد استفاده از MAC Table را مشاهده کرد. افزایش سریع این عدد نشانهای از حمله یا رفتار غیرعادی است. همچنین بررسی Output Drops در Interfaceهای Uplink میتواند نشان دهد که گلوگاه در کجاست. اگر CPU نیز بالا باشد، احتمال درگیر شدن Control Plane وجود دارد.
جمعبندی: تصویر واقعی از آنچه درون سوئیچ رخ میدهد
وقتی ARP Flood رخ میدهد، مشکل فقط افزایش چند ARP Request نیست. در عمق سوئیچ، CAM Table با Entryهای جدید پر میشود، Bufferها تحت فشار قرار میگیرند، Queueها اشباع میشوند، Fabric ممکن است دچار Oversubscription شود و در برخی شرایط CPU نیز افزایش مصرف را تجربه میکند. نتیجه نهایی میتواند از کندی جزئی تا از کار افتادن کامل شبکه متغیر باشد. درک دقیق این رفتار داخلی به شما کمک میکند که هنگام مشاهده Broadcast غیرعادی، فقط به سطح ظاهری مشکل نگاه نکنید، بلکه به معماری داخلی سوئیچ نیز توجه داشته باشید.
RP Flood در ظاهر یک پدیده ساده لایه دو است، اما در عمل میتواند تمام لایههای عملکردی یک سوئیچ، از Data Plane تا Control Plane، را تحت تأثیر قرار دهد. مهندس شبکهای که رفتار داخلی را میشناسد، سریعتر ریشه مشکل را تشخیص میدهد و از تبدیل یک Flood ساده به بحران سراسری جلوگیری میکند.
دیدگاه شما
